Socratic Omni: A simple AI mathematician powered by LLM 🦉
Through this blog, I want to highlight my project — Socratic Omni that combines education with Machine Learning to help students solve mathematics problems. This is an account of the entire experiment — starting from the formulation of the problem statement till result analysis.
Abstract💡
AI is transforming many areas of our lives, and mathematics is no exception. In this article, we’ll take a look at how we built an AI-powered mathematician that can solve all kinds of geometric problems. Using Streamlit for a user-friendly interface and GPT-4o for the brains behind it, this tool offers clear, step-by-step solutions and stunning visualizations to help you understand even the trickiest concepts.
We’ll dive into how it works, from taking your problem description and crunching the numbers to displaying easy-to-understand visual aids. Plus, insights from a demo video will show you the magic in action — solving problems in real-time, offering interactive elements, and providing comprehensive solutions that make learning geometry fun and engaging.
Code: https://github.com/akshaybahadur21/Socratic

Preface 🖼️
Imagine having a sophisticated mathematician at your disposal — one that not only tackles your most challenging questions but also guides you through each step with detailed explanations and dynamic visualizations. This is achieved by integrating Streamlit, a powerful framework for creating interactive web applications, with GPT-4, OpenAI’s latest and most advanced large language model.
We are at the forefront of AI development, embracing the advances in large language models (LLMs) and multimodal AI capabilities. GPT-4o is a testament to these advances, capable of processing and generating human-like text with unprecedented accuracy. Additionally, the integration of multimodal capabilities allows this tool to interpret and generate not only text but also visual content, bridging the gap between language, images, and videos.
Throughout this article, we will take you on a comprehensive journey from the conceptualization to the realization of Socratic Omni. You will see how it processes natural language descriptions of geometric problems, generates detailed solutions, and employs sophisticated visualization techniques to enhance understanding.

Streamlit 🕯️
Streamlit is a Python library for rapid development of interactive web applications. Its simplicity and ease of use have made it popular among data scientists and machine learning engineers for building and sharing data-driven applications.

For Socratic Omni, we have used streamlit-webrtc, which is an extension for Streamlit that enables real-time media processing capabilities directly within Streamlit apps. It leverages the WebRTC (Web Real-Time Communication) protocol, allowing for seamless integration of audio and video streaming features.
OpenAI GPT -4o 🤖
The GPT-4 Omni model (GPT-4o) integrates text, vision, and audio processing into a single, cohesive model, making it one of the most advanced AI systems available. Here are some of the key features:
- Multimodal Integration: GPT-4o processes and generates text, visual, and audio content, allowing it to handle complex tasks involving multiple input types.
- Enhanced Performance: It outperforms previous models in multilingual tasks, audio processing, and visual comprehension. It has set new benchmarks in tests like the General Knowledge test (MMLU) and the M3Exam for diagrams.
- Efficiency: Designed to be twice as fast and 50% cheaper to operate than its predecessors, GPT-4o uses a new tokenizer to optimize language processing, reducing memory requirements and processing time.
- Advanced Capabilities: Excelling in speech recognition and translation, GPT-4o can distinguish emotional nuances in audio and interpret complex visual content, including facial expressions and video analysis.

Mediapipe🚰
Google’s MediaPipe is a cutting-edge open-source framework that transforms the landscape of real-time multi-modal solutions. Offering a versatile set of tools, from hand tracking to pose estimation, MediaPipe empowers developers to create immersive applications across diverse industries. Its seamless integration with TensorFlow, efficient inference models, and cross-platform compatibility make it a go-to choice for projects ranging from augmented reality experiences to health and fitness applications.
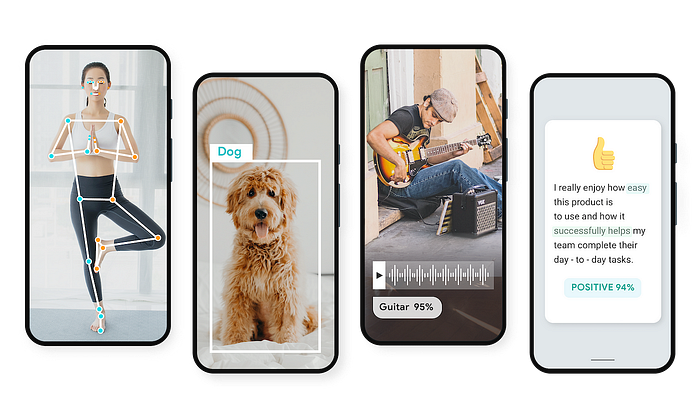
MediaPipe’s strength lies in its ability to handle diverse tasks across multiple modalities. For Socratic Omni, we will be focussing on the Hand Tracking module.
Hand Tracking: MediaPipe’s hand tracking module enables real-time tracking of hand movements in video streams. This is particularly useful for gesture recognition, sign language interpretation, and virtual touch interfaces.
Previous Versions 🌴
There have been 2 previous releases for Project Socratic:
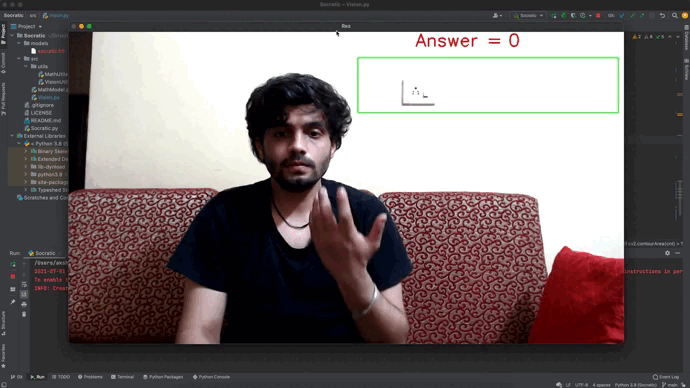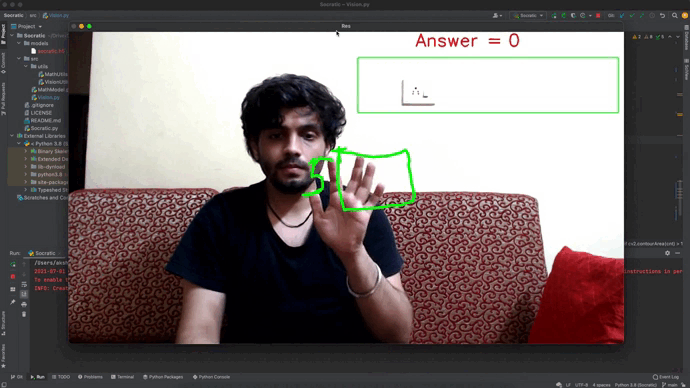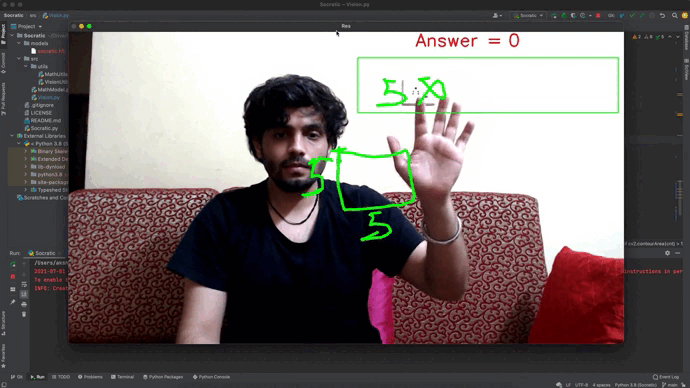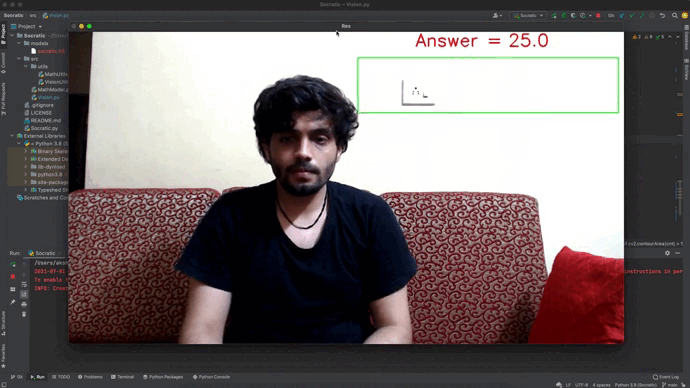
- Socratic Solver: Socratic Solver uses Machine Learning to solve mathematical equations related to 2D shapes. The version provides a drawing board area and an equation writer area (marked in the green rectangle). The user can use the drawing board area to draw the geometrical shape, followed by writing the related equation in the writer area to solve the equation.
- Socratic Plotter: Socratic Plotter uses Machine Learning to plot mathematical equations related to 2D shapes. The version provides an equation writer area (marked in the green rectangle). The user can write the mathematical equation in the writer area to generate a plot for that two-dimensional shape.
Inspiration 🖼️
This project has been heavily inspired by multiple AI-based mathematical tools by companies such as Google, Microsoft, and OpenAI.
- Socratic by Google: Socratic by Google is a powerful educational tool designed to help high school and college students with their studies. Acquired by Google in 2019, the app leverages advanced AI technologies and uses both text and speech recognition to identify questions posed by students, either by typing or taking a photo of their homework. It then searches for the most relevant learning resources online to provide detailed explanations and guide students through the problem-solving process.
- Microsoft Math Solver: Microsoft Math Solver leverages advanced AI and machine learning technologies, and this tool offers comprehensive support for arithmetic, algebra, trigonometry, calculus, and more. Users can input problems by typing them in, scanning handwritten notes, or taking pictures of printed problems. Microsoft Math Solver then processes these inputs to provide step-by-step solutions, making it an invaluable learning aid for understanding mathematical concepts and problem-solving techniques.

- Khanamigo by Khan Academy: Khanmigo is an AI-powered tutor developed by Khan Academy, utilizing GPT-4 to provide personalized learning experiences. Integrated with Khan Academy’s extensive course library, Khanmigo offers contextually relevant assistance, guiding students through problems rather than just providing answers. It supports a wide range of subjects, including math, science, humanities, and coding, making it a versatile educational tool.
Modules 🔥
At its core, Socratic Omni uses a combination of cameras, text input, and machine learning algorithms to analyze a mathematical problem drawn by the user through the webcam and generate the correct steps to be followed to solve that problem. These capabilities are achieved through a systematic pipeline that encompasses these submodules:
- Keypoint Detection: Socratic Omni utilizes a pre-trained MediaPipe landmark model based on a Convolutional Neural Network. This model accepts incoming video feeds from webcams (256 x 256 pixels’ RGB values) and outputs a result of shape [33, 5]. This translates to the detection of 33 key points, each having associated X, Y, and Z coordinates, along with visibility and presence factors.

- LLM Knowledge: Socratic Omni uses State-of-the-Art Large Language GPT-4o, which is trained on vast datasets encompassing diverse topics. This extensive training enables LLMs to excel in natural language processing, contextual understanding, and providing accurate, relevant answers. By supporting a wide range of subjects, LLMs make Socratic Omni a versatile educational tool. The interactive and conversational abilities of LLMs guide students through problem-solving processes, enhancing their learning experience. As LLMs continue to improve, so will the capabilities of tools like Socratic Omni, offering increasingly effective and personalized educational assistance.

- Multimodal Feedback: The Socratic Omni project leverages multimodal capabilities that allow the AI to interpret and respond to queries not only through text but also by analyzing visual content that is drawn on the screen by the user. By combining these different modes of information, Socratic Omni can offer more accurate and contextually rich assistance, enhancing the overall learning experience for students.
Implementation 👨🔬
Setup
- Run
pip install requirements.txtto resolve the code dependencies. - Run the
SocraticOmni.pyto start the Streamlit application. - Start a web browser and visit
https://localhost:8051to start the Socratic Omni Application. - Select the webcam from the source list and click the
Startbutton to stream the webcam feed.
Execution
python -m streamlit run SocraticOmni.pySnippets ✂️
In this section, we will delve into key aspects of the Python implementation. Let’s start by examining the project structure.
├── Socratic
├── .github
├── .streamlit
├── src
├── utils
├── MathUtils.py
├── streamlitUtils.py
.
.
├── HandDetector.py
├── MathModel.py
├── PlotModel.py
├── Plotter.py
└── Vision.py
├── LICENSE
├── Socratic.py
├── SocraticOmni.py
├── requirements.txt
└── Readme.mdRemember, this repository also contains two legacy versions of Socratic — Socratic Solver and Socratic Plotter. For Socratic Omni, the two main aspects of the code are written in the following two Python files:
- src/utils/streamlitUtils.py: This contains all the utility and helper functions used for Socratic Omni.
- SocraticOmni.py: This Python file contains the main logic for the Streamlit application that integrates OpenAI’s GPT-4o with computer vision to create an interactive educational tool. It employs a WebRTC streamer to capture live video, enabling real-time interaction through hand gestures detected by a custom hand detector using OpenCV.
Let’s now break down the SocraticOmni.py file for a better understanding of how the application works
1. Initial Setup
This snippet shows the initial setup where various configurations and dependencies are initialized:
import queue
from streamlit_webrtc import webrtc_streamer, WebRtcMode
import av
import base64
from src.utils.streamlitUtils import *
image = set_streamlit_header()
openai_client, detector, brush_thick, eraser_thick, rectKernel, options, counter_map, blkboard = set_basic_config()
if 'contents' not in st.session_state:
st.session_state['contents'] = []
border = False
else:
border = True
if "messages" not in st.session_state:
st.session_state.messages = []- This code imports necessary libraries and modules.
- The
set_streamlit_header()function sets the Streamlit header. set_basic_config()initializes several important configurations such as OpenAI client, hand detector, and drawing parameters.- Session states
contentsandmessagesare initialized if they don't already exist.
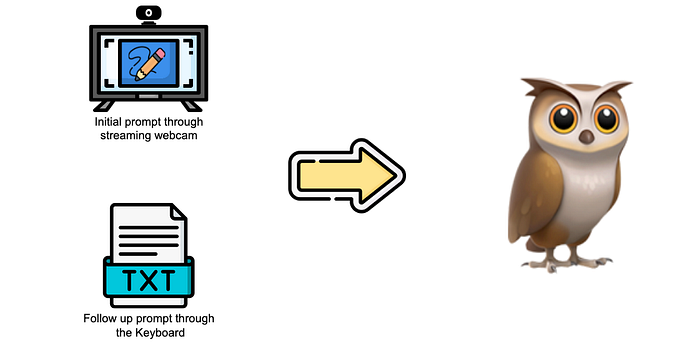
2. Generating User Prompt
Function to generate a user prompt for the AI model:
def generate_user_prompt():
prompt = r"""
#### User Prompt:
- You are Socratic 🦉 - an LLM powered mathematician for humans.
- You are given the figure of a geometrical structure with related inputs.
- You have to find the area of the figure and mention the steps
"""
return prompt3. Callback Function for Frame Processing
This callback function is for processing video frames in a WebRTC stream using OpenCV. It detects hand gestures to draw or erase on a virtual blackboard. Here is a detailed explanation of the key parts of the code:
def callback(frame, xp=0, yp=0):
img = frame.to_ndarray(format="bgr24")
img = cv2.flip(img, 1)
img = detector.find_hands(img)
landmark_list = detector.find_position(img, draw=False)
if len(landmark_list) != 0:
_, x1, y1 = landmark_list[8] # Tip of Index Finger
_, x2, y2 = landmark_list[12] # Tip of Middle Finger
fingers = detector.fingers()
# Code for sketching, rubbing on the virtual board
# This snippet has been broken down to improve readibility.
# Follow the next couple of sections where we break down the fuction.
# Visit https://github.com/akshaybahadur21/Socratic/blob/main/SocraticOmni.py#L46-L108 for details
return av.VideoFrame.from_ndarray(img, format="bgr24")Let’s break down the callback function mentioned above
3.1. Frame Preprocessing
img = frame.to_ndarray(format="bgr24")
img = cv2.flip(img, 1)Converts the frame to a NumPy array in BGR format and flips it horizontally to create a mirror effect.
3.2. Hand Detection
img = detector.find_hands(img)
landmark_list = detector.find_position(img, draw=False)Uses a hand detector to identify hands and their landmarks in the image.
3.3. Gesture Detection
if len(landmark_list) != 0:
_, x1, y1 = landmark_list[8] # Tip of Index Finger
_, x2, y2 = landmark_list[12] # Tip of Middle Finger
fingers = detector.fingers()- Check if landmarks are detected and extract coordinates of the index and middle fingertips.
- Determines which fingers are up using the
fingersmethod.
3.4. Drawing and Erasing Logic
if len(fingers) == 5:
if fingers[1] == 1 and fingers[2] == 1 and fingers[0] == 0 and fingers[3] == 0 and fingers[4] == 0:
cv2.rectangle(img, (x1 - 25, y1 - 25), (x2 + 25, y2 + 25), (0, 0, 255), cv2.FILLED)
if xp == 0 and yp == 0:
xp, yp = x1, y1
cv2.line(blkboard, (xp, yp), (x1, y1), (0, 0, 0), eraser_thick)
counter_map["go"] = 0
xp, yp = x1, y1
elif fingers[1] == 1 and fingers[0] == 0 and fingers[2] == 0 and fingers[3] == 0 and fingers[4] == 0:
cv2.circle(img, (x1, y1), 15, (255, 0, 255), cv2.FILLED)
counter_map["go"] = 0
if xp == 0 and yp == 0:
xp, yp = x1, y1
cv2.line(blkboard, (xp, yp), (x1, y1), (0, 255, 0), brush_thick)
xp, yp = x1, y1Identifies specific gestures to perform drawing and erasing:
- When the index and middle fingers are up and others are down, it draws a rectangle and erases on the blackboard.
- When only the index finger is up, it draws a circle and writes on the blackboard.
3.5. Gesture for Processing Blackboard Content
elif fingers[0] == 1 and fingers[1] == 0 and fingers[2] == 0 and fingers[3] == 0 and fingers[4] == 0:
xp, yp = 0, 0
blackboard_gray = cv2.cvtColor(blkboard, cv2.COLOR_RGB2GRAY)
blur1 = cv2.medianBlur(blackboard_gray, 15)
blur1 = cv2.GaussianBlur(blur1, (5, 5), 0)
thresh1 = cv2.threshold(blur1, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)[1]
blackboard_cnts, _ = cv2.findContours(thresh1.copy(), cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
if len(blackboard_cnts) >= 1:
bounding_boxes = []
for cnt in sorted(blackboard_cnts, key=cv2.contourArea, reverse=True):
if cv2.contourArea(cnt) > 800:
x, y, w, h = cv2.boundingRect(cnt)
bounding_boxes.append((x, y))
bounding_boxes.append((x + w, y + h))
box = cv2.minAreaRect(np.asarray(bounding_boxes))
(x1, y1), (x2, y2), (x3, y3), (x4, y4) = cv2.boxPoints(box)
a1 = min(x1, x2, x3, x4)
a2 = max(x1, x2, x3, x4)
b1 = min(y1, y2, y3, y4)
b2 = max(y1, y2, y3, y4)
cv2.rectangle(img, (int(a1), int(b1)), (int(a2), int(b2)), (0, 255, 0), 2)
digit = blackboard_gray
counter_map["go"] += 1
if counter_map["go"] > 20:
result_queue.put(True)
counter_map["go"] = 0
cv2.imwrite("math.png", digit)When only the thumb is up, it processes the blackboard content:
- Converts the blackboard to grayscale and applies median and Gaussian blurs.
- It uses thresholding to create a binary image and finds the contours of the drawn content.
- Draws a bounding rectangle around the largest contour and processes the detected region as the digit.
- If the gesture is held long enough, saves the processed image as “math.png” and signals the result queue.
3.6. Updating the Blackboard and Final Output
else:
xp, yp = 0, 0
counter_map["go"] = 0
gray = cv2.cvtColor(blkboard, cv2.COLOR_BGR2GRAY)
_, inv = cv2.threshold(gray, 50, 255, cv2.THRESH_BINARY_INV)
if img.shape[0] == 720 and img.shape[1] == 1280:
inv = cv2.cvtColor(inv, cv2.COLOR_GRAY2BGR)
img = cv2.bitwise_and(img, inv)
img = cv2.bitwise_or(img, blkboard)
return av.VideoFrame.from_ndarray(img)- Resets the drawing coordinates if no specific gesture is detected.
- Converts the blackboard to grayscale, inverts the colors, and blends it with the current video frame.
- Ensures the final image is of the correct resolution and returns it as a video frame.
4. Setting up the WebRTC Streamer
This section sets up the WebRTC streamer for video input and processing:
with col1:
with st.container(height=590):
ctx = webrtc_streamer(key="socratic",
mode=WebRtcMode.SENDRECV,
async_processing=True,
rtc_configuration={
"iceServers": [{"urls": ["stun:stun.l.google.com:19302"]}]
},
video_frame_callback=callback,
media_stream_constraints={"video":
{"width": {"ideal": 1280, "min": 1280},
"height": {"ideal": 720, "min": 720}},
"audio": False,
}
)- This snippet creates a WebRTC streamer within a Streamlit container.
- It configures the streamer to send and receive video frames, processes them asynchronously, and uses a STUN server for network traversal.
- The
callbackfunction processes each video frame, handling the core image processing functionality of the application. For details on the callback function, see section 3. Callback Function
5. Displaying Chat and Processing User Inputs
This section handles the display of the chat interface and processes user inputs:
with col2:
if ctx is not None:
with st.container(height=532):
col1, col2, col3 = st.columns([4, 2, 4])
with col1:
st.write(' ')
with col2:
st.markdown("""## Socratic""")
with col3:
st.write(' ')
while ctx.state.playing:
try:
chat = None
result = None
try:
result = result_queue.get(timeout=1.0)
except queue.Empty:
result = False
chat_queue = st.session_state['contents']
if len(chat_queue) > 0:
chat = chat_queue[-1]
if result and chat is None:
with st.chat_message("user", avatar="👩🚀"):
st.write_stream(response_generator(prompt, 0.01))
col1, col2, col3 = st.columns([2, 3, 3])
with col1:
st.write(' ')
with col2:
st.image('math.png', width=300, caption='Image submitted by user')
with col3:
st.write(' ')
st.session_state.messages.append({"role": "user", "content": chat})
st.session_state['contents'] = []
with st.chat_message("assistant", avatar="🦉"):
base64_image = encode_image("math.png")
stream = openai_client.chat.completions.create(
model=st.session_state["openai_model"],
messages=[
{"role": "system",
"content": "You are a helpful assistant that responds in Markdown. Help me with my math homework!"},
{"role": "user", "content": [
{"type": "text",
"text": f"Here is a follow-up prompt for the image you submitted: {chat}"},
{"type": "image_url", "image_url": {
"url": f"data:image/png;base64,{base64_image}"}
}
]}
],
stream=True,
)
response = st.write_stream(stream)
st.session_state.messages.append({"role": "assistant", "content": response})
except queue.Empty:
result = None- While the WebRTC context is active, it checks for new results and chat messages, handling them accordingly.
- When a new chat message is detected, it displays the user input and submits the prompt to the OpenAI API for a response.
- The assistant’s response is then processed and displayed in the chat interface.
6. Generating the Follow-up Prompts
This part adds an input box for users to enter follow-up prompts:
with st.container(border=False):
with st.container():
prompt = st.chat_input(placeholder="Follow-up prompt for 🦉", key='content', on_submit=chat_content)
if prompt is not None:
chat_queue.append(prompt)- This snippet creates an input box for users to submit follow-up prompts to the AI assistant.
- When a prompt is submitted, it is added to the chat queue for processing.
Check out the complete demo below:
Conclusion ✨
The Socratic Omni project represents a significant advancement in educational technology. It combines the robust capabilities of large language models (LLMs) like GPT-4o with multimodal functionality to deliver a comprehensive, interactive learning experience. By leveraging state-of-the-art natural language processing and the ability to interpret both text and images, Socratic Omni provides personalized, accurate, and contextually relevant assistance to make learning more interactive and accessible.
This project not only enhances accessibility to quality education but also fosters deeper understanding and critical thinking among students. As AI technology continues to evolve, the potential for further innovations in educational tools like Socratic Omni promises to transform how students learn and engage with their studies, paving the way for a brighter, more informed future.
References 🌟
- Socratic - Get unstuck. Learn better: Socratic by Google
- Hello GPT-4o: OpenAI
- Streamlit • A faster way to build and share data apps
- Streamlit-webrtc — by Whitephx
Made with ❤️ and🦉 by Akshay
